Bài 05 - Cải thiện và kết hợp các hàm
- Hàm bậc cao
filterany
- Hàm lambda
- Ưu tiên và tính kết hợp
- Hàm Curried
- ứng dụng một phần
- Áp dụng và soạn các hàm
- Toán tử
$ - Toán tử
.
- Toán tử
- Phong cách tự do
Video bài giảng
Hàm bậc cao
1. Lấy các hàm khác làm đối số hoặc
2. Kết quả trả về là một hàm.
Bởi vì chúng ta có thể lấy các hàm làm đầu vào, trả về chúng dưới dạng kết quả và gán chúng cho các biến, nên chúng giống như bất kỳ giá trị nào khác. Vì vậy, chúng ta nói rằng các hàm là công dân hạng nhất .
Hãy bắt đầu với một ví dụ cổ điển. Hãy tưởng tượng rằng bạn có một hàm mà bạn thường dùng hai lần (vì lý do nào đó). Như thế này:
complexFunc1 :: Int -> Int
complexFunc1 x = x + 1
func1 :: Int -> Int
func1 x = complexFunc1 (complexFunc1 x)
complexFunc2 :: Int -> Int
complexFunc2 x = x + 2
func2 :: Int -> Int
func2 x = (complexFunc2 (complexFunc2 x)) + (complexFunc2 (complexFunc2 x))
Đây là một ví dụ phóng đại, nhưng bạn có thể thấy một mô hình bắt đầu xuất hiện như thế nào. Bạn luôn luôn sử dụng complexFunc1 và complexFunc2 hai lần! Ngay khi nhìn thấy mô hình này, chúng ta nhận ra rằng mình có thể làm tốt hơn. Điều gì sẽ xảy ra nếu chúng ta tạo một hàm nhận hai tham số–một hàm và một giá trị–và áp dụng hàm cho giá trị đó hai lần!
Chúng ta có thể làm điều đó bằng cách viết đơn giản:
applyTwice :: (a -> a) -> a -> a
applyTwice f x = f (f x)
Ở đây, Khai báo Kiểu khác với những Khai báo trước đó. Phần (a -> a) chỉ ra rằng tham số đầu tiên là một hàm nhận một giá trị kiểu a và trả về một giá trị cùng kiểu. Tham số thứ hai chỉ là một giá trị của Kiểu a và toàn bộ hàm applyTwice trả về một giá trị của Kiểu a.
Và trong phần nội dung của hàm, bạn có thể thấy rằng nó nhận tham số đầu tiên (hàm f), áp dụng nó cho x và sau đó áp dụng f lại cho kết quả. Vì vậy, chúng ta đang áp dụng hàm f hai lần.
Và thế là xong! Chúng ta đã tạo một hàm bậc cao!
Chúng ta có thể sử dụng hàm applyTwice để đơn giản hóa mã trước đó như thế này:
func1' :: Int -> Int
func1' x = applyTwice complexFunc1 x
func2' :: Int -> Int
func2' x = (applyTwice complexFunc2 x) + (applyTwice complexFunc2 x)
Đây là một ví dụ đơn giản, nhưng các hàm bậc cao là một tính năng cực kỳ mạnh mẽ. Nhiều đến mức chúng ở khắp mọi nơi! Trên thực tế, bạn có thể tạo Ngôn ngữ dành riêng cho lĩnh vực của riêng mình bằng cách sử dụng các hàm bậc cao! Nhưng hãy thực hiện từng bước một. Hãy bắt đầu bằng cách sử dụng hai hàm bậc cao đi kèm với Haskell.
Hàm filter
Hãy bắt đầu với hàm filter:
:t filter
filter :: forall a. (a -> Bool) -> [a] -> [a]
Hàm này nhận một vị từ (predicate - một hàm trả về giá trị boolean) a -> Bool và một danh sách các phần tử có kiểu a và lọc các phần tử của danh sách đã cung cấp cho vị từ.
Ví dụ: nếu chúng ta chỉ muốn lọc các số chẵn từ danh sách từ 1 đến 20, chúng ta có thể thực hiện một số việc như:
filter even [1..20]
[2,4,6,8,10,12,14,16,18,20]
Hoặc, đối với một điều kiện liên quan hơn, chúng ta có thể lọc từ danh sách các loại trái cây chỉ những loại có chứa chữ cái 'a':
fruitWithA = filter tempFunct ["Apple", "Banana", "Pear", "Grape", "Wood"]
where tempFunct x = 'a' `elem` x
fruitWithA
["Banana","Pear","Grape"]
Như bạn có thể thấy, bạn cũng có thể định nghĩa một hàm trong một where mệnh đề để chuyển nó làm vị ngữ của hàm filter.
Hàm any
Chúng ta cũng có Hàm any:
-- Only for lists: any :: (a -> Bool) -> [a] -> Bool
Hàm này cũng nhận một vị từ và một danh sách các phần tử. Nhưng cái này kiểm tra xem có tồn tại bất kỳ phần tử nào trong danh sách mà vị từ nắm giữ hay không.
Ví dụ: ở đây chúng ta đang kiểm tra xem có bất kỳ phần tử nào của danh sách lớn hơn 4 không. Nếu chỉ có một phần tử lớn hơn, any trả về True, nếu không, nó trả về False:
biggerThan4 x = x > 4
any biggerThan4 [1,2,3,4]
False
Một cách thực tế hơn để sử dụng any là kiểm tra xem chúng ta còn xe nào trên trang web bán xe của mình không:
cars = [("Toyota",0), ("Nissan",3), ("Ford",1)]
biggerThan0 (_,x) = x > 0
any biggerThan0 cars
True
Trong biggerThan0, chúng ta khớp mẫu trên bộ dữ liệu để trích xuất số lượng ô tô và kiểm tra xem nó có lớn hơn 0 hay không. Sau đó, chúng ta đang sử dụng any để kiểm tra xem có bất kỳ cặp nào trong danh sách còn lại ít nhất một ô tô hay không.
Ok, chúng ta đã thấy rất nhiều ví dụ về các hàm lấy các hàm khác làm tham số. Nhưng còn những hàm trả về hàm dưới dạng kết quả thì sao? Chúng ta sẽ đến đó. Trước tiên, chúng ta sẽ tìm hiểu về rút gọn lambda và các hàm curried (áp dụng từng phần).
Hàm lambda
Thuật ngữ hàm lambda xuất phát từ hệ thống toán học gọi là phép tính lambda. Bản thân nó đã là một chủ đề hấp dẫn và mạnh mẽ, nhưng hôm nay, chúng ta sẽ xem xét nó từ quan điểm của một lập trình viên thực tế.
Hàm lambda (còn được gọi là hàm ẩn danh) là một định nghĩa hàm không có tên.
Ví dụ: đây là cách mà một hàm lambda nhận hai đối số và nhân chúng với nhau ( $f(x,y)=x*y$ ), trong Haskell, nó sẽ nhìn như thế này:
\x y -> x * y
- Dấu gạch chéo ngược
\ở đầu cho chúng ta biết rằng đây là hàm lambda. - Tên của tham số (trong trường hợp này là
x y) mà hàm lấy làm đầu vào. - Mũi tên (
->) phân tách đầu vào khỏi phần thân. - Và mọi thứ sau mũi tên là phần thân của hàm.
Hầu hết các ngôn ngữ lập trình hiện đại cũng có hàm ẩn danh. Nhưng không phải tất cả chúng đều hoạt động theo cùng một cách.
Tại sao bạn cần quan tâm tới hàm lambda?
Nghe có vẻ vô dụng vì làm sao bạn có thể sử dụng một hàm không có tên? Bạn không có cách nào gọi nó sau này!
Trên thực tế, đó là một thành phần mạnh mẽ của ngôn ngữ! Thông qua khóa học này, chúng ta sẽ gặp nhiều tình huống trong đó các biểu thức lambda là thực tế. Đối với người mới bắt đầu, bạn có thể sử dụng biểu thức lambda để tránh đặt tên cho các hàm mà bạn sẽ chỉ sử dụng một lần!
Bản thân điều này rất hữu ích, nhưng nó thực sự tỏa sáng khi làm việc với các hàm bậc cao! Ví dụ: hãy xem ví dụ trước:
biggerThan4 x = x > 4
any biggerThan4 [1,2,3,4]
False
Chức năng đó biggerThan4 sẽ không được sử dụng ở bất kỳ nơi nào khác, nhưng nó sẽ tồn tại mãi mãi trong môi trường của chúng ta. Ngoài ra, đó là một hàm cực kỳ đơn giản! Tên cảu hàm còn dài hơn thân!
Bằng cách sử dụng các biểu thức lambda, chúng ta có thể tạo và sử dụng biggerThan4 làm tham số cho any tất cả cùng một lúc như sau:
any (\x -> x > 4) [1,2,3,4]
False
Chúng ta cũng có thể sử dụng các biểu thức lambda để đơn giản hóa các hàm khác. Hãy xem lại fruitWithA hàm:
fruitWithA = filter tempFunct ["Apple", "Banana", "Pear", "Grape", "Wood"]
where tempFunct x = 'a' `elem` x
fruitWithA
["Banana","Pear","Grape"]
Chúng ta có thể đơn giản hóa fruitWithA bằng cách loại bỏ tempFunct và thay thế nó bằng hàm lambda:
filter (\x -> 'a' `elem` x) ["Apple", "Banana", "Pear", "Grape", "Wood"]
["Banana","Pear","Grape"]
Và, tất nhiên, vì các hàm lambda chỉ là các biểu thức nên bạn có thể sử dụng chúng ở bất kỳ đâu mà một biểu thức có thể được sử dụng. Ngay cả với chính chúng:
(\x -> x*2 + 1) 3
7
Nếu bạn cần thêm ví dụ, hãy tiếp tục xem/đọc. Các hàm lambda sẽ là một công cụ có giá trị để dễ dàng hình dung quá trình nấu cà ri.
Ngay bây giờ, chúng ta sẽ dành vài phút để tìm hiểu về mức độ ưu tiên và tính kết hợp.
Ưu tiên và tính kết hợp
Quyền ưu tiên
Precedence cho biết mức độ ưu tiên của toán tử (được biểu thị bằng một số từ 0 đến 9). Nếu chúng ta sử dụng hai toán tử có mức độ ưu tiên khác nhau, toán tử có mức độ ưu tiên cao hơn sẽ được áp dụng trước. Có nghĩa là các toán tử ưu tiên cao hơn liên kết chặt chẽ hơn!
Chúng ta có thể lấy quyền ưu tiên cho một toán tử bằng lệnh thông tin :i.
:i (+) -- infixl 6 +
:i (*) -- infixl 7 *
1 + 2 * 3 -- Tương tự như 1 + (2 * 3)
7
infixl 6 + và infixl 7 * được gọi là khai báo fixity .
Bởi vì phép nhân có ưu tiên 7, cao hơn ưu tiên 6 của phép cộng, nên kết quả là 7 chứ không phải 9.
Và điều gì xảy ra khi hai toán tử có cùng quyền ưu tiên? Đây là khi tính kết hợp phát huy tác dụng.
Tính liên kết
Khi chúng ta sử dụng :i lệnh trước đó, nó cũng trả về từ khóa infixl. Đây là tính kết hợp của toán tử.
Khi hai toán tử có cùng mức độ ưu tiên, tính kết hợp cho bạn biết bên nào (trái với infixl hoặc phải với infixr) sẽ được đánh giá trước.
Ví dụ:
Các toán tử
(+)và(*)có tính kết hợp trái, có nghĩa là chúng đánh giá vế trái trước.Toán
(:)tử có tính kết hợp phải, có nghĩa là nó đánh giá phía bên phải trước.Toán
(==)tử không có tính kết hợp (infix), có nghĩa là nếu bạn sử dụng nhiều hơn một, bạn cần có dấu ngoặc đơn để biểu thị thứ tự.1 + 2 + 3 + 4 -- infixl: Tương tự như ((1 + 2) + 3) + 4
1 : 2 : 3 : [] -- infixr: Tương tự như 1 : (2 : (3 : []))
True == (False == False) -- infix: If you remove parenthesis, you'll get an error.
10
[1,2,3]
True
Và, tất nhiên, bạn có thể thay đổi thứ tự đánh giá bằng cách sử dụng dấu ngoặc đơn:
:i (**) -- infixr 8 **
2**3**4 -- infixr: Tương tự như 2 ** (3 ** 4)
(2**3)**4
Cuối cùng, chúng ta có thể xác định mức độ ưu tiên và tính kết hợp khi tạo toán tử của riêng mình. Như thế này:
x +++ y = x + y -- Creating +++ operator
infixl 7 +++ -- Setting fixity of operator
1 +++ 2 * 3 -- 9
9
Bây giờ, kết quả là 9 vì +++ và * đều là liên kết trái và có cùng mức độ ưu tiên.
- Các toán tử không có khai báo tính cố định rõ ràng là
infixl 9 - Ứng dụng hàm ("toán tử khoảng trắng - dấu cách") luôn có mức ưu tiên cao nhất (hãy nghĩ mức ưu tiên là 10).
Hàm Curried
Currying là quá trình thay đổi một hàm sao cho thay vì nhận nhiều đầu vào, nó chỉ nhận một đầu vào duy nhất và trả về một hàm chấp nhận đầu vào thứ hai, v.v.
Trong Haskell, tất cả các hàm được coi là Curried! Nghĩa là, tất cả các hàm trong Haskell chỉ nhận một đối số!
Để minh họa điều này, hãy xem hàm này:
add3 :: Int -> Int -> Int -> Int
add3 x y z = x + y + z
Nó có vẻ giống như một hàm đa tham số. Chúng ta biết rằng ứng dụng hàm ("toán tử khoảng trắng") luôn có mức độ ưu tiên cao nhất và liên kết với bên trái, vì vậy nếu chúng ta làm rõ thêm điều đó, chúng ta sẽ nhận được:
add3 :: Int -> Int -> Int -> Int
((add3 x) y) z = x + y + z
Và nếu chúng ta kiểm tra tính ưu tiên của mũi tên hàm (->):
:i (->) -- infixr -1 ->
Chúng ta thấy rằng nó liên kết với bên phải! Vì vậy, một cách rõ ràng hơn để viết Khai báo của add3 hàm là:
add3 :: Int -> (Int -> (Int -> Int))
((add3 x) y) z = x + y + z
add3 1 2 3
6
Hoàn toàn tương ứng với định nghĩa của hàm! Tuy nhiên, để làm cho nó rõ ràng một cách tường minh, chúng ta sẽ làm rõ ràng việc currying bằng cách sử dụng các hàm lambda.
Bắt đầu với định nghĩa trước:
add3 :: Int -> (Int -> (Int -> Int)) -- Tương tự nhu: add3 :: Int -> Int -> Int -> Int
((add3 x) y) z = x + y + z -- Tương tự nhu: add3 x y z = x + y + z
Chúng ta sẽ di chuyển từng tham số từ bên trái của dấu = sang bên phải. Tạo cùng một hàm nhiều lần nhưng được viết khác nhau. Vì vậy, bắt đầu với z (tham số ngoài cùng), một add3 hàm tương đương thực hiện chính xác như hàm ban đầu có thể được viết như sau:
add3 :: Int -> (Int -> (Int -> Int))
(add3 x) y = \z -> x + y + z
Bây giờ, add3 là một hàm lấy hai số (x y) và trả về một hàm lấy một số khác (z) và cộng ba số lại với nhau.
Nếu chúng ta làm điều đó một lần nữa cho giá trị thứ hai:
add3 :: Int -> (Int -> (Int -> Int))
add3 x = \y -> (\z -> x + y + z)
Bây giờ, add3 là một hàm lấy một số (x) và trả về một hàm lấy một số (y) trả về một hàm lấy một số (z) và cộng ba số lại với nhau.
Và nếu chúng ta làm điều đó một lần nữa:
add3 :: Int -> (Int -> (Int -> Int))
add3 = \x -> (\y -> (\z -> x + y + z))
Chúng ta nhận được đó add3 là một cái Tên trả về một hàm lấy một số (x) và trả về một hàm lấy một số (y) trả về một hàm lấy một số (z) cộng ba số lại với nhau.
Đó là một hành trình khá dài, nhưng chúng ta đã xoay sở để làm cho currying trở nên rõ ràng!
Và bây giờ, cách Khai báo được viết có ý nghĩa hơn nhiều! Mỗi khi bạn thay thế một tham số, kết quả là nó sẽ trả về một hàm mới. Đó là cho đến khi bạn thay thế cái cuối cùng mang lại cho bạn kết quả cuối cùng.
Và bởi vì ký hiệu -> là liên kết phải, chúng ta có thể xóa dấu ngoặc đơn ít sử dụng của cả Khai báo và định nghĩa để có được mã rõ ràng hơn:
add3 :: Int -> Int -> Int -> Int
add3 = \x -> \y -> \z -> x + y + z
Và bây giờ, ví dụ, nếu chúng ta áp dụng hàm cho 3 tham số như thế này:
add3 1 2 3
6
Đây là những gì xảy ra từng bước (tôi đã thêm dấu ngoặc đơn để hỗ trợ trực quan):
add3 :: Int -> (Int -> (Int -> Int))
add3 = \x -> (\y -> (\z -> x + y + z))
---
add3 1 = \y -> (\z -> 1 + y + z) :: Int -> (Int -> Int)
add3 1 2 = \z -> 1 + 2 + z :: Int -> Int
add3 1 2 3 = 1 + 2 + 3 :: Int
Vì vậy, bên cạnh việc là người bắt đầu cuộc trò chuyện thú vị tại câu lạc bộ, điều này hữu ích như thế nào đối với bạn? Chà… với các hàm chưa được curried, nếu bạn cung cấp ít tham số hơn những tham số được yêu cầu, bạn sẽ gặp lỗi. Nhưng bởi vì, trong Haskell, tất cả các hàm đều được curried, bạn có thể tận dụng nó để sử dụng Áp dụng một phần!
Áp dụng một phần
Áp dụng một phần trong Haskell có nghĩa là bạn cung cấp ít đối số hơn số lượng tối đa mà hàm chấp nhận.
Kết quả (như chúng ta đã thấy trước đó) là một hàm mới nhận phần còn lại của các tham số mà bạn không cung cấp cho hàm ban đầu.
Như một ví dụ thực tế về mức độ hữu ích của tính năng này, giả sử bạn có một hàm được sử dụng để tạo email ở định dạng name.lastName@domain. Các tham số bạn cung cấp là tên miền, tên và họ:
createEmail :: String -> String -> String -> String
createEmail domain name lastName = name ++ "." ++ lastName ++ "@" ++ domain
Bây giờ, công ty của bạn có hai cộng đồng là khách hàng, có hai tên miền khác nhau. Bạn không muốn người dùng của mình phải viết ra tên miền mỗi lần, vì vậy bạn tạo 2 hàm để áp dụng một phần tên miền của họ:
createEmailTeckel :: String -> String -> String
createEmailTeckel = createEmail "teckel-owners.com"
createEmailSCL :: String -> String -> String
createEmailSCL = createEmail "secret-cardano-lovers.com"
createEmailTeckel "Robertino" "Martinez"
createEmailSCL "Vitalik" "Buterin"
"Robertino.Martinez@teckel-owners.com"
"Vitalik.Buterin@secret-cardano-lovers.com"
Lưu ý rằng điều này là có thể bởi vì miền là tham số đầu tiên trong hàm createEmail. Vì vậy, thứ tự của các đối số là quan trọng.
Nếu vì lý do nào đó, tham số bạn muốn áp dụng không phải là tham số đầu tiên và bạn không được phép viết lại hàm hiện có, bạn có thể tạo một hàm trợ giúp:
-- With partial application:
createEmailJohn :: String -> String -> String
createEmailJohn lastName domain = createEmail domain "John" lastName
-- Without partial application:
createEmail' :: String -> String -> String -> String
createEmail' name lastName domain = createEmail domain name lastName
Và bởi vì các toán tử chỉ là các hàm trung tố, chúng ta cũng có thể áp dụng chúng một phần!
Ví dụ: nhớ lại ví dụ trước về hàm bậc cao:
any (\x -> x > 4) [1,2,3,4]
False
Trong hàm chúng ta truyền dưới dạng tham số, chúng ta cần so sánh xem đầu vào có lớn hơn không 4. Và > toán tử đã là một hàm nhận hai tham số và so sánh xem tham số đầu tiên có lớn hơn tham số thứ hai hay không. Vì vậy, chúng ta có thể áp dụng một phần tham số bên phải để có được kết quả tương tự:
any (>4) [1,2,3,4]
False
Áp dụng một phần của toán tử trung tố được gọi là section .
Và tôi không chắc bạn có để ý không, nhưng chúng ta vừa thay thế tham số thứ hai (tham số bên phải). Điều thú vị về các phần là bạn có thể áp dụng một phần mặt thuận tiện hơn:
(++ "ing") "Think" -- Tương tự như \x -> x ++ "ing"
("Anti" ++) "library" -- Tương tự như \x -> "Anti" ++ x
"Thinking"
"Antilibrary"
Toán tử này - rất đặc biệt và bạn không thể áp dụng nó một phần. -1 được phân tích cú pháp dưới dạng chữ -1 thay vì toán tử phân đoạn - được áp dụng cho 1. Hàm subtract tồn tại để giải quyết vấn đề này.
Áp dụng và soạn các hàm
Toán tử Ứng dụng hàm - $
Nếu chúng ta kiểm tra xem toán tử ứng dụng hàm được định nghĩa như thế nào trong Haskell, thì nhìn nó có vẻ hơi… kỳ lạ:
($) :: (a -> b) -> a -> b
f $ x = f x
Chúng ta thấy rằng nó nhận vào một hàm f và một biến x, sau đó áp dụng hàm đó cho biến (f x). Vì vậy, có vẻ như toán tử này là dư thừa vì nó hoạt động giống như một ứng dụng hàm thông thường (f x).
Và bạn biết nó là cái gì! Tuy nhiên, có một sự khác biệt nhỏ nhưng đáng kể giữa chúng:
- Toán tử "khoảng trắng" có mức độ ưu tiên liên kết bên trái cao nhất.
- Toán tử ứng dụng hàm (
$) có quyền ưu tiên liên kết phải thấp nhất:infixr 0 $.
Bạn có thể thấy sự khác biệt nếu chúng ta làm rõ điều này bằng cách sử dụng dấu ngoặc đơn:
f g h x = ((f g) h) x
f $ g $ h x = f (g (h x))
Để làm ví dụ về cách điều này thay đổi mọi thứ, hãy xem các biểu thức sau:
(2 *) 3 + 4 -- Tương tự như: ((2 *) 3) + 4
(2 *) $ 3 + 4 -- Tương tự như: (2 *) (3 + 4)
max 5 4 + 2 -- Tương tự như: ((max 5) 4) + 2
max 5 $ 4 + 2 -- Tương tự như: (max 5) (4 + 2)
Như bạn có thể thấy trong các ví dụ trước, khi sử dụng $, toàn bộ biểu thức bên phải của nó được áp dụng làm tham số cho hàm bên trái. Vì vậy, bạn có thể thấy cách sử dụng $ giống như các dấu ngoặc đơn bao quanh tất cả mọi thứ ở phía bên phải của nó.
Điều này đưa chúng ta đến cách sử dụng chính của $: đơn giản là thay thế và bỏ qua dấu ngoặc đơn!
Trong biểu thức sau, có 3 cơ hội để loại bỏ dấu ngoặc đơn, vì vậy chúng ta loại bỏ chúng:
-- All these expressions are equivalent:
show ((2**) (max 3 (2 + 2)))
show $ (2**) (max 3 (2 + 2))
show $ (2**) $ max 3 (2 + 2)
show $ (2**) $ max 3 $ 2 + 2
Điều này làm cho mã của bạn dễ đọc và dễ hiểu hơn.
Tất nhiên, bạn có thể làm nhiều việc hơn ngoài việc xóa dấu ngoặc đơn, nhưng đó là điều bạn sẽ dùng hầu hết thời gian. Vì vậy, chúng ta sẽ để nó ở đó và bắt đầu tìm hiểu về toán tử thành phần hàm (.)!
Thành phần hàm
Chúng ta đã đề cập đến khái niệm về thành phần hàm trong bài học đầu tiên của chúng ta. Vì vậy, nếu bạn không chắc chắn về nó, hãy kiểm tra nó! Nhưng, chỉ là một sự bồi dưỡng và trong một vài từ:
Khi chúng ta kết hợp hai hàm, chúng ta tạo ra một hàm mới tương đương với việc gọi hai hàm theo trình tự khi hàm thứ nhất lấy đầu ra của hàm thứ hai làm đầu vào.
Chúng ta có thể làm điều này với dấu ngoặc đơn. Ở đây, hàm f lấy đầu vào là kết quả của việc áp dụng hàm g cho x:
f (g x)
Như một ví dụ có lẽ quá phức tạp, chúng ta có thể làm điều gì đó như thế này:
complicatedF :: [Int] -> Bool
complicatedF x = any even (filter (>25) (tail ( take 10 x)))
Ở đây, chúng ta đang sáng tác khá nhiều! Chính xác là 3 lần! Và như bạn có thể thấy, điều này khá khó đọc, vì vậy sơ đồ có thể hữu ích:
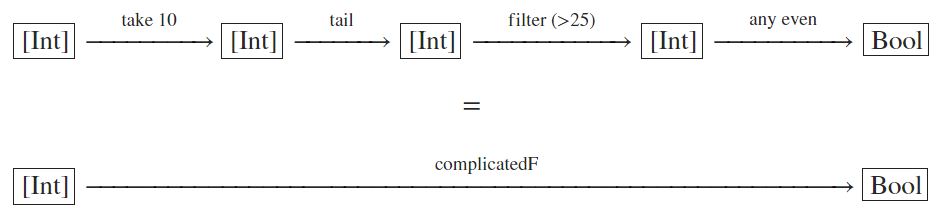
Chúng ta lấy một danh sách Int làm đầu vào, sau đó sử dụng take 10 để lấy 10 phần tử đầu tiên của danh sách, sau đó sử dụng kết quả làm đầu vào để tail trả về 9 phần tử cuối cùng, sau đó sử dụng kết quả của danh sách đó làm đầu vào để filter (>25) lọc các giá trị lớn hơn hơn 25, và cuối cùng, lấy kết quả của nó làm đầu vào để any even kiểm tra xem có bất kỳ số chẵn nào còn lại trong danh sách hay không.
Sơ đồ đã giúp ích, nhưng nếu tôi nói với bạn rằng có một cách để có thứ gì đó rõ ràng và dễ hiểu nhưng trong mã của chúng ta thì sao?
Điều này có thể được thực hiện bằng cách rút gọn thành phần hàm cho một toán tử. Và bởi vì, trong toán học, ký hiệu tổng hợp là một chiếc nhẫn giống như một dấu chấm, nên chúng ta sẽ sử dụng một dấu chấm:
(.) :: (b -> c) -> (a -> b) -> a -> c
f . g = \x -> f (g x)
infixr 9 .
Ở đây, chúng ta thấy rằng . toán tử nhận hai hàm (f :: b -> c và g :: a -> b) và kết hợp chúng bằng cách sử dụng hàm lambda để chỉ ra rằng toàn bộ f . g biểu thức trả về một hàm nhận tham số x :: a, áp dụng g cho nó để nhận giá trị Kiểu b và cuối cùng áp dụng f cho nó nhận giá trị kiểu c.
Điều quan trọng cần lưu ý là đầu vào f nhận một giá trị có cùng Kiểu với đầu ra của g. Vì vậy, hàm kết quả lấy đầu vào là một giá trị cùng Kiểu với đầu vào của g là (a) và trả về ở đầu ra một giá trị cùng Kiểu với đầu ra f của ' (c).
Vì vậy, bây giờ chúng ta có toán tử mới này, complicatedF bây giờ hàm trông như thế này:
complicatedF :: [Int] -> Bool
complicatedF x = any even . filter (>25) . tail . take 10 $ x
Wow dễ đọc hơn! Bạn có thể nói mọi thứ mà hàm thực hiện chỉ bằng một cái nhìn nhanh!
Ngoài ra, hãy lưu ý rằng mọi hàm ở cả hai phía của toán tử . đều nhận một đối số duy nhất hoặc được áp dụng một phần cho đến khi nó nhận một đối số duy nhất.
Nếu chúng ta viết lại ví dụ từ chương toán tử ứng dụng bằng cách sử dụng toán tử dấu chấm, chúng ta sẽ nhận được:
show ((2**) (max 3 (2 + 2)))
show . (2**) . max 3 $ 2 + 2
Như bạn có thể thấy, $ và . có thể làm cho mã của bạn rõ ràng và ngắn gọn. Nhưng hãy cảnh giác để không lạm dụng chúng! Bạn có thể sẽ có một kết quả tồi tệ nhất!
Và bây giờ, như là một cách cuối cùng để làm cho hàm của bạn dễ đọc hơn, thưa quý vị và các bạn, chúng ta trình bày phong cách kiểu tự do!! 👏👏👏
Phong cách tự do
Theo kiểu tự do (point-free style -còn gọi là lập trình ngầm), các định nghĩa hàm không khai báo các đối số.
Vì vậy, thay vì làm điều này:
fourOrLarger :: Int -> Int
fourOrLarger x = max 4 x
add1 :: Int -> Int
add1 x = 1 + x
Chúng ta có thể viết thế này:
fourOrLarger :: Int -> Int
fourOrLarger = max 4
add1 :: Int -> Int
add1 = (1+)
Các hàm cũng làm như vậy, nhưng bây giờ, chúng ta không ràng buộc rõ ràng đối số và sử dụng nó bên trong thân hàm. Điều đó ngầm định trong định nghĩa nhưng vẫn rõ ràng trong Khai báo.
Chức năng Point-free có ưu điểm là:
- Nhỏ gọn hơn.
- Dễ hiểu.
- Sạch hơn, vì chúng loại bỏ thông tin dư thừa.
Vì vậy, chúng ta có thể sử dụng kiểu Point-free để thay đổi điều này:
complicatedF :: [Int] -> Bool
complicatedF x = any even . filter (>25) . tail . take 10 $ x
Vào cái này:
complicatedF :: [Int] -> Bool
complicatedF = any even . filter (>25) . tail . take 10
Điều này cho chúng ta biểu thức cuối cùng của complicatedF.
Phong cách này đặc biệt hữu ích khi rút ra các chương trình hiệu quả bằng tính toán và nói chung, tạo thành kỷ luật tốt. Nó giúp người viết và người đọc suy nghĩ về việc soạn các hàm ở mức cao thay vì xáo trộn dữ liệu ở mức thấp.
Điều này kết thúc bài học hôm nay. Hôm nay chúng ta đã học được nhiều khái niệm và cách thức mới để cải thiện và kết hợp các hàm của mình. Có thể có rất nhiều thứ phải tiếp thu cùng một lúc, nhưng tất cả những khái niệm này đều quan trọng. Vì vậy, hãy chắc chắn rằng bạn hiểu rõ về chúng trước khi tiếp tục với khóa học.
Nguồn bài viết tại đây
