Bài 09 - Tạo Kiểu được tham số hóa và đệ quy
- Kiểu tham số hóa
- Tham số hóa
typetương đồng (synonyms) - Tham số hóa Kiểu
data
- Tham số hóa
- Kiểu dữ liệu đệ quy
TweetSequencecủaNodeTreecủaNode
- Loại (Kinds)
- Từ khóa
newType
Video bài giảng
Kiểu tham số hóa
Một hàm tạo giá trị lấy các giá trị làm tham số và tạo ra một giá trị .
Một hàm tạo kiểu lấy Kiểu làm tham số và tạo ra một kiểu .
Chúng ta có thể sử dụng các hàm tạo kiểu với cả Kiểu tương đồng và kiểu mới. Hãy bắt đầu với Kiểu tương đồng.
Tham số hóa Kiểu tương đồng
Quay trở lại Kiểu tương đồng cuối cùng của chúng ta, chúng ta đã có:
type Name = String
type Address = (String, Int)
type Person = (Name, Address)
bob = ("Bob Smith", ("Main St.", 555)) :: Person
Hãy hình dung rằng, sau khi sử dụng một thời gian, chúng ta phát hiện ra rằng chúng ta cũng phải xác định các công ty theo id số và nhà cung cấp theo id chữ và số của họ.
Chúng ta có thể làm điều gì đó như:
type Address = (String, Int)
type Name = String
type CompanyId = Int
type ProviderId = String
type Person = (Name, Address)
type Company = (CompanyId, Address)
type Provider = (ProviderId, Address)
bob = ("Bob Smith", ("Main St.", 555)) :: Person
io = (584264, ("Cardano St.", 999)) :: Company
google = ("Google LLC", ("Amphitheatre Parkway", 1600)) :: Provider
Trong trường hợp này, chúng ta thêm bốn Kiểu tương đồng. Các CompanyId, ProviderId, Company, và Provider là tương đồng.
Chúng ta nhận được kết quả mong muốn của mình, nhưng phải trả giá bằng việc lặp lại cùng một cấu trúc ba lần (Person, Company và Provider là các bộ với 'Cái gì đó' và một kiểu Address). Một cách tiếp cận khác là xác định một Kiểu tương đồng tham số.
Ví dụ, chúng ta có thể tạo kiểu Entity a:
type Entity a = (a, Address)
Để xác định một Kiểu tương đồng tham số, chúng ta phải chỉ ra tham số ở bên trái của dấu hiệu = và sử dụng nó ở bên phải. Tương tự như với các chức năng.
Và bây giờ, mỗi khi sử dụng Entity a, chúng ta có thể điều chỉnh Kiểu a theo nhu cầu của mình. Ví dụ:
type Name = String
type Address = (String, Int)
type CompanyId = Int
type ProviderId = String
type Entity a = (a, Address)
bob = ("Bob Smith", ("Main St.", 555)) :: Entity Name
io = (584264, ("Cardano St.", 999)) :: Entity CompanyId
google = ("Google LLC", ("A. Parkway", 1600)) :: Entity ProviderId
other = (True, ("Some street", 0)) :: Entity Bool
Lần này, chúng ta thêm ba Kiểu tương đồng nữa. Các CompanyId, ProviderId, và Entity a là Kiểu tương đồng.
Và bên dưới, chúng ta có bốn giá trị khác nhau với bốn Kiểu khác nhau. Tất cả chúng đều có được bằng cách truyền một kiểu khác cho hàm tạo Kiểu cùng loại.
Lưu ý rằng:
Entitybản thân nó là một hàm tạo kiểu, không phải là một kiểu, vì vậy nó không có giá trị nào, nó chỉ là một kiểuEntity.Entity Name,Entity CompanyId,Entity ProviderId, vàEntity Boollà các Kiểu hoàn toàn khác nhau!
Chúng ta cũng có thể sử dụng đa tham số. Ví dụ, sử dụng Kiểu tương đồng Address để tạo thành một cặp. Vì vậy, chúng ta có thể khái quát hóa Entity a ở mức cao hơn để có thể truyền hai giá trị vào và trở thành Kiểu được tham số hóa:
type Name = String
type Address = Entity String Int
type CompanyId = Int
type ProviderId = String
type Entity a b = (a, b)
bob = ("Bob Smith", ("Main St.", 555)) :: Entity Name Address
io = (584264, ("Cardano St.", 999)) :: Entity CompanyId Address
google = ("Google LLC", ("A. Parkway", 1600)) :: Entity ProviderId Address
other = (True, ("Some street", 0)) :: Entity Bool Address
Như bạn có thể thấy, bây giờ Entity a b có hai Kiểu tham số. Và Address là tương đồng với một trường hợp cụ thể trong Entity a b đó tham số đầu tiên là a String và tham số thứ hai là Int.
Tất nhiên, bây giờ cái tên Entity không còn nhiều ý nghĩa nữa và Kiểu của chúng ta bắt đầu trở nên phức tạp. Tôi chỉ muốn cho bạn thấy rằng bạn có thể sử dụng nhiều tham số Kiểu và đó không phải là vấn đề lớn. Nhưng đó là khá nhiều cho Kiểu tương đồng. Chúng rất hữu ích để cung cấp ngữ cảnh bổ sung khi cần và chúng cung cấp tính linh hoạt nhất định cho phép các tham số Kiểu. Nhưng ngoài ra, chúng khá nhàm chán.
Hãy cùng tìm hiểu về tham số hóa Kiểu dữ liệu!
Tham số hóa Kiểu dữ liệu
Để thêm tham số Kiểu trong khi xác định kiểu mới, bạn thực hiện tương tự như với chức năng và Kiểu tương đồng tham số hóa. Thêm tham số vào bên trái của dấu = và (tùy chọn) sử dụng nó ở bên phải:
data Box a = Empty | Has a deriving (Show)
Ở đây, chúng ta đang xác định một Kiểu hoàn toàn mới. Một Kiểu đại diện cho một hộp có chứa các giá trị.
Trong trường hợp này, Box là một hàm tạo kiểu nhận một biến kiểu a. Vì vậy, chúng ta có thể có các giá trị kiểu Box Bool, Box Char, Box Float v.v.
Và chúng ta có hai hàm tạo giá trị:
:t Empty
:t Has
Empty :: forall a. Box a
Has :: forall a. a -> Box a
Trả về Empty khi hộp trống. Trong trường hợp này, Empty thuộc Kiểu Box a, nghĩa là nó đa hình. Chúng ta không biết Kiểu gì bên trong vì nó trống rỗng!
Và Has hàm tạo giá trị khi hộp có giá trị bên trong. Trong trường hợp này, chúng ta có một giá trị bên trong, vì vậy Kiểu của Box a sẽ phụ thuộc vào Kiểu của giá trị đó.
Ví dụ:
box1 = Has "What's in the box?!"
:t box1
box2 = Empty
:t box2
box1 :: Box [Char]
box2 :: forall a. Box a
Chúng ta cũng có thể sửa đổi và kết hợp các giá trị bên trong các hộp:
-- data Box a = Empty | Has a
box = Has (1 :: Int)
addN :: Num a => a -> Box a -> Box a
addN _ Empty = Empty
addN n (Has a) = Has (a + n)
addN 3 box
Has 4
-- data Box a = Empty | Has a
addBoxes :: Num a => Box a -> Box a -> Box a
addBoxes _ Empty = Empty
addBoxes Empty _ = Empty
addBoxes (Has a) (Has b) = Has (a + b)
addBoxes (Has 3) (Has 7)
addBoxes (Has 5) Empty
Has 10
Empty
Và nếu chúng ta muốn trích xuất giá trị bên trong hộp thì sao? Trường hợp của Has a hàm tạo giá trị rất dễ dàng, chúng ta chỉ cần khớp mẫu và trả về a. Nhưng còn trường hợp hộp rỗng thì sao?
Chà, chúng ta có thể yêu cầu trả về một giá trị mặc định nếu hộp trống. Bằng cách đó, chúng ta luôn trả về một giá trị!
Vì vậy, nếu chúng ta dịch này thành mã, chúng ta nhận được:
-- data Box a = Empty | Has a
extract :: a -> Box a -> a
extract def Empty = def
extract _ (Has x) = x
extract 'a' Empty
extract 0 (Has 15)
extract 0 Empty
extract [] (Has [1,2,3,4])
'a'
15
0
[1,2,3,4]
Chúng ta có thể tiếp tục tạo ra nhiều chức năng hơn cho Box a, nhưng vẫn còn rất nhiều điều cần giải quyết, vì vậy hãy tiếp tục!
Chúng ta cũng có thể sử dụng các hàm tạo kiểu với cú pháp bản ghi. Hãy hình dung chúng ta cũng muốn tùy chọn sử dụng các cách khác để thể hiện màu sắc trong hình dạng của mình. Trước đây, chúng ta đã sử dụng String các giá trị và ghi tên màu. Nhưng các tình huống khác có thể đảm bảo các định dạng khác nhau. Giống như giá trị thập lục phân hoặc RGB. Vì vậy, tốt hơn nếu chúng ta tham số hóa kiểu của mình như thế này:
data Shape a
= Circle
{ position :: (Float, Float)
, radius :: Float
, color :: a
}
| Rectangle
{ position :: (Float, Float)
, width :: Float
, height :: Float
, color :: a
}
deriving (Show)
Bây giờ, trường màu có thể thuộc bất kỳ Kiểu nào và hình dạng của chúng ta có thể thuộc Kiểu Shape String, Shape Int, v.v.
Ví dụ:
circleS = Circle { position = (1,2), radius = 6, color = "Green"}
:t circleS
type RGB = (Int,Int,Int)
circleRGB = Circle { position = (1,2), radius = 6, color = (0, 128, 0) :: RGB}
:t circleRGB
circleS :: Shape [Char]
circleRGB :: Shape RGB
Và tất cả các thuộc tính khác của Kiểu bản ghi vẫn được áp dụng.
Bây giờ chúng ta đã biết tất cả các cách tạo kiểu này, chúng ta sẽ xem xét thêm một vài ví dụ để mở rộng kiến thức. Chúng ta sẽ ném một mũi tên trúng hai đích và tìm hiểu về đệ quy khi học môn này!
Kiểu dữ liệu đệ quy
Chúng ta có thể sử dụng các Kiểu tương đồng bên trong các Kiểu tương đồng khác. Nhưng vì lý do kỹ thuật, chúng ta không thể định nghĩa các Kiểu tương đồng đệ quy. Tuy nhiên, chúng ta có thể định nghĩa Kiểu dữ liệu đệ quy.
Dòng trạng thái Tweet
Tình hình là Elon Musk muốn xây dựng lại Twitter bằng Haskell. Và bạn đang phỏng vấn cho vị trí này. Câu hỏi đầu tiên là xác định Kiểu dữ liệu cho một tweet. Một tweet có nội dung của nó, số lượng tin nhắn lại, lượt thích, bình luận, siêu dữ liệu, v.v. Đó sẽ là một Kiểu dữ liệu khổng lồ, nhưng người phỏng vấn không quan tâm đến các chi tiết. Anh ấy muốn bạn trình bày ý tưởng chung.
Vì vậy, bạn cung cấp điều này:
data Tweet = Tweet
{ contents :: String
, likes :: Int
, comments :: [Tweet]
} deriving (Show)
:t Tweet -- Type of the Tweet constructor
Tweet :: String -> Int -> [Tweet] -> Tweet
Chỉ cần 1 hàm tạo với 3 trường. Bạn đã sử dụng cú pháp bản ghi vì bạn biết Kiểu này cuối cùng sẽ chứa nhiều trường hơn và sẽ rất cồng kềnh nếu sử dụng cú pháp thông thường. Bạn cũng nhận ra rằng một nhận xét cho một tweet chỉ là một tweet khác, vì vậy bạn có thể sử dụng đệ quy [Tweet] làm Kiểu nhận xét bên trong Tweet kiểu dữ liệu.
Và để kiểm tra nó, bạn tạo ra một Tweet giá trị thực tế:
tweet :: Tweet
tweet = Tweet "I'm angry about something! >.<" 5
[ Tweet "Me too!" 0 []
, Tweet "It makes me angry that you're angry" 2
[ Tweet "I have no idea what's happening" 3 [] ]
]
Người phỏng vấn thích ý tưởng của bạn nhưng nghi ngờ về việc làm việc với kiểu người như thế này sẽ dễ dàng như thế nào. Và để chứng minh rằng điều đó cực kỳ dễ dàng, bạn đã viết một chức năng để đo lường mức độ tương tác dựa trên số lượt thích và phản hồi của tweet và tất cả các tweet mà tweet đó tạo ra có:
engagement :: Tweet -> Int
engagement Tweet {likes = l, comments = c} = l + length c + sum (map engagement c)
engagement tweet
13
Mẫu engagement chức năng chỉ khớp với các trường nó cần, sau đó nó thêm lượt thích và lượng bình luận của tweet đó. Và cùng với đó, nó đã thêm tổng các số được tạo bằng cách ánh xạ đệ quy engagement hàm mà chúng ta đang tạo cho tất cả các tweet trong danh sách nhận xét.
Người phỏng vấn ấn tượng đến mức cô ấy dừng cuộc phỏng vấn trong thời gian ngắn và đề nghị bạn một vị trí cấp cao. Nhưng bạn đã từ chối lời đề nghị khi biết rằng hiện tại, lương của tất cả nhân viên Twitter được trả bằng Dodge coin.
Vì vậy, bạn chuyển sang cuộc phiêu lưu tiếp theo.
Sequence của Nodes
Sau khi hoàn thành thành công quy trình phỏng vấn của Twitter và từ chối lời đề nghị của họ, sự tự tin của bạn tăng vọt và bạn quyết định thử việc tại Google.
Các cuộc phỏng vấn ban đầu đều ổn, nhưng đã đến lúc thực sự: Cuộc phỏng vấn kỹ thuật! Bạn xuất hiện đúng giờ và người phỏng vấn cũng vậy. Chúng ta đang chuẩn bị cho một khởi đầu tốt. Và đây là câu hỏi đầu tiên:
"Viết kiểu dữ liệu đại diện cho một chuỗi node tuyến tính trong đó mỗi node chứa một giá trị và trỏ đến phần còn lại của chuỗi."
Vừa đủ dễ! Vì vậy, bạn cần một Kiểu dữ liệu tương tự như Box a chúng ta đã tạo trước đây:
data Box a = Empty | Has a
Hàm Empty tạo đại diện cho một node trống và Has hàm tạo là một node có giá trị bên trong. Đó là một khởi đầu tốt. Vấn đề là bạn cần chứa một chuỗi các hộp này.
May mắn thay, bạn biết rằng bạn có thể truyền nhiều tham số cho một hàm tạo giá trị, vì vậy bạn chỉ cần thêm một hộp khác làm tham số thứ hai của hàm Has tạo:
data Box a = Empty | Has a (Box a)
:t Has
Has :: forall a. a -> Box a -> Box a
Tham số mới đó có nghĩa là hàm Has tạo giá trị hiện chứa một giá trị và một hộp có thể chứa một giá trị khác và một hộp khác, v.v.
Và chúng ta có một kiểu dữ liệu là một chuỗi tuyến tính của các hộp (hoặc các node) trong đó mỗi hộp có một giá trị và trỏ đến phần còn lại của các hộp.
Và điều đó thật tuyệt vời! Nhưng bạn đã làm tất cả những điều này trong đầu, và người phỏng vấn bắt đầu lo lắng về sự im lặng kéo dài của bạn. Vì vậy, bạn đã giải thích lý do nhưng thay đổi từ "Box" bằng "Sequende" và "Has" bằng "Node" vì đó là ngôn ngữ của câu hỏi. Vì vậy, bạn đã trình bày giải pháp như thế này:
data Sequence a = EmptyS | Node a (Sequence a) deriving (Show)
:t Node
node :: forall a. a -> Sequence a -> Sequence a
Kiểu dữ liệu đó đại diện cho một chuỗi các node có thể trống hoặc có một node chứa giá trị và trỏ đến phần còn lại của chuỗi. Nó vẫn giống như trước đây, nhưng việc thay đổi tên khiến bạn nghĩ khác về những gì đang xảy ra.
Và để chứng minh rằng nó hoạt động như mong đợi, bạn tạo một vài giá trị:
-- data Sequence a = EmptyS | Node a (Sequence a)
sequence1 :: Sequence a
sequence1 = EmptyS -- A sequence of just one empty node
sequence2 :: Sequence Char
sequence2 = Node 'a' EmptyS -- A sequence of 2 nodes
sequence3 :: Sequence Bool
sequence3 = Node True (Node False EmptyS) -- A sequence of 3 nodes
sequence4 :: Sequence Integer
sequence4 = Node 1 (Node 2 (Node 3 EmptyS)) -- A sequence of 4 nodes
Ngay sau đó, người phỏng vấn nhìn thẳng vào mắt bạn và hỏi:
"Và điều này hữu ích như thế nào?"
Bạn do dự trong một giây. Và đó là khi bạn mơ hồ nhớ đến một khóa học Haskell mà bạn đã học cách đây rất lâu—vâng, các bài giảng video cũng có thể được đệ quy. Bạn mỉm cười và nói: "Ồ, tôi sẽ cho bạn biết điều này hữu ích như thế nào."
Và tiến hành sửa đổi một chút kiểu dữ liệu để tạo điểm nhấn. Đây là những gì bạn đã làm:
infixr 5 :->
data Sequence a = EmptyS | a :-> (Sequence a) deriving (Show)
:t (:->)
(:->) :: forall a. a -> Sequence a -> Sequence a
Vì các hàm tạo giá trị chỉ là các hàm, nên bạn cũng có thể tạo các hàm tạo giá trị trung tố—với lưu ý rằng chúng phải bắt đầu bằng dấu hai chấm (:).
Trong trường hợp này, bạn xác định :-> hàm tạo giá trị (mũi tên lạ) lấy giá trị của node làm đối số đầu tiên và phần còn lại của chuỗi làm đối số thứ hai.
Vì vậy, giá trị trước đó sequence4 bây giờ trông như thế này:
sequence4 :: Sequence Integer
sequence4 = 1 :-> 2 :-> 3 :-> EmptyS -- A sequence of 3 nodes + empty node
Nhìn quen quen, đúng không? Chính xác! Đó là một danh sách!! Nếu chúng ta so sánh hai bên cạnh nhau, điều đó khá rõ ràng:
sequence4' :: [] Integer -- Same as [Integer]
sequence4' = 1 : 2 : 3 : [] -- A list with 3 elements + empty list
Và nếu chúng ta so sánh kiểu của chúng ta với cách các danh sách được định nghĩa trong Haskell:
data Sequence a = EmptyS | a :-> (Sequence a)
data [] a = [] | a : [a]
Chúng ta thấy rằng chúng gần như cùng Kiểu, nhưng các danh sách có một số cú pháp đặc biệt "thêm đường" để làm cho chúng dễ sử dụng hơn.
Và đó là lý do tại sao bạn chọn tính cố định là infixr 5. Bởi vì nó giống như hàm tạo :.
Sau khi trình bày bằng chứng đó, tiện ích của Kiểu này là hiển nhiên. Bạn vừa tạo lại Kiểu danh sách và danh sách ở khắp mọi nơi!
Người phỏng vấn hài lòng, nhưng anh ấy chỉ mới bắt đầu! Và anh hỏi:
"Bây giờ hãy viết một hàm để kiểm tra xem một phần tử cụ thể có nằm trong chuỗi này hay không."
Người phỏng vấn hài lòng, nhưng anh ấy chỉ mới bắt đầu! Và anh hỏi:
Không có gì! Bạn phải triển khai chức năng elem cho Kiểu mới của mình giống như cách nó được triển khai cho danh sách:
-- data Sequence a = EmptyS | a :-> (Sequence a)
elemSeq :: (Eq a) => a -> Sequence a -> Bool
elemSeq _ EmptyS = False
elemSeq x (y :-> ys) = x == y || elemSeq x ys
Bạn xác định hàm elemSeq nhận một giá trị kiểu a và một giá trị kiểu Sequence a và trả về một Bool. Trong đó, a là một dạng của lớp Kiểu so sánh (vì bạn sẽ kiểm tra so sánh).
Bạn có hai hàm tạo, vì vậy bạn bắt đầu với hai phương trình. Một cho hàm tạo EmptyS và một cho hàm tạo :->.
Nếu dãy trống, bạn không cần quan tâm đến giá trị khác vì bạn biết nó sẽ không nằm trong một node trống.
Và nếu chuỗi có ít nhất một node không trống, bạn sẽ so khớp mẫu để trích xuất giá trị của node đầu tiên (y), kiểm tra xem giá trị đó có bằng với giá trị được cung cấp dưới dạng tham số đầu tiên (x) hay không và áp dụng đệ quy hàm elemSeq cho cùng giá trị ban đầu và phần còn lại của danh sách.
Nếu ít nhất một phần tử của danh sách bằng với giá trị được cung cấp, bạn muốn trả về True. Vì vậy, bạn sử dụng || toán tử lấy hai phép toán luận và trả về True nếu một trong hai là True. Bằng cách đó, ngay khi bạn nhận được một khớp mẫu, bạn sẽ nhận giá trị True cho đến tận cuối cùng. Và bạn sẽ biết giá trị đó nằm trong dãy.
Sử dụng chức năng này, chúng ta có thể kiểm tra xem một phần tử có nằm trong chuỗi các node của chúng ta hay không như thế này:
seq5 = 'a' :-> 'b' :-> '4' :-> '%' :-> EmptyS
elemSeq 'c' seq5
elemSeq '%' seq5
False
True
"Làm tốt đấy." - người phỏng vấn nói - "Nhưng tôi có một vấn đề với điều này. Tôi có hàng chục nghìn phần tử, và nếu chúng ta phải kiểm tra từng phần tử một theo trình tự, thì sẽ mất rất nhiều thời gian!"
Bạn đã thấy điều này đến từ cách xa một dặm và nói: "Không thành vấn đề! Nếu chúng ta có các giá trị được sắp xếp theo thứ tự, chúng ta có thể sử dụng Cây tìm kiếm nhị phân!"
Tree của Node
Người phỏng vấn đã đúng! Hãy hình dung bạn có 10.000 mục để xem qua. Nếu bạn đi từng người một, nó sẽ mất mãi mãi! Vậy bạn làm gì?
Hãy nghĩ về lần cuối cùng bạn tìm kiếm một từ trong từ điển. Không, không phải trên máy tính. Tôi có nghĩa là một từ điển vật lý thực tế. Bạn đã làm nó như thế nào? Bạn đã đi đến trang đầu tiên, tìm từ ở đó, sau đó đến trang thứ hai, v.v.? KHÔNG! Bạn thẳng lên mở từ điển ở giữa! Và khi bạn thấy rằng từ đó không có ở đó, bạn đã chọn một trong các nửa dựa trên thứ tự của bảng chữ cái, chia đôi nửa đó và kiểm tra lại từ đó. Bằng cách đó, mỗi lần bạn kiểm tra, bạn đã giảm được một nửa kích thước của vấn đề. Đó được gọi là "thuật toán tìm kiếm nhị phân" và nó tốt hơn nhiều so với tìm kiếm tuyến tính. Bạn hỏi tốt hơn bao nhiêu?
Ví dụ, nếu từ điển có 10.000 trang, khi tra cứu tuyến tính, trường hợp xấu nhất (từ nằm ở cuối) sẽ là tra hết 10.000 trang. Nhưng nếu chúng ta sử dụng thuật toán tìm kiếm nhị phân, trường hợp xấu nhất là chúng ta cần kiểm tra 13 trang! 13! Đó là nó! Bạn có thể thấy đây là một công cụ thay đổi cuộc chơi về hiệu quả như thế nào.
Vì vậy, chúng ta muốn tạo một cấu trúc dữ liệu cho phép chúng ta dễ dàng tìm kiếm theo cách đó. Có một vài chúng ta có thể sử dụng. Nhưng một trong những cái nổi tiếng nhất là cấu trúc dữ liệu Cây tìm kiếm nhị phân (còn gọi là Cây nhị phân được sắp xếp). Và nó trông như thế này:
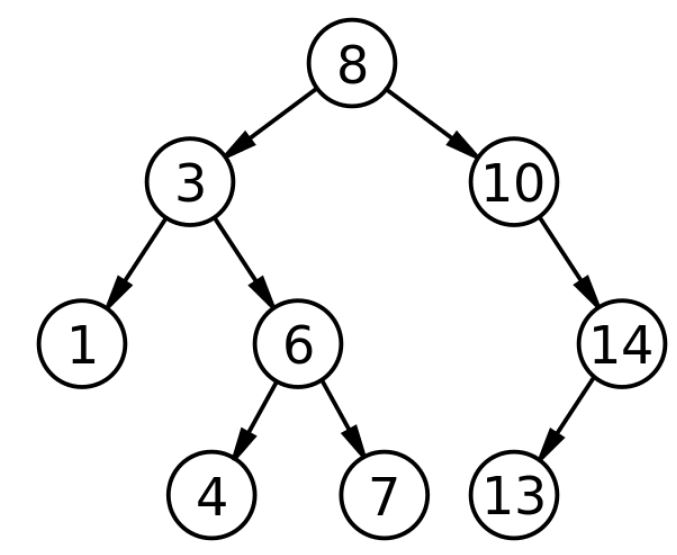
Trong một cây nhị phân:
- Mỗi node có thể có nhiều nhất hai node con
- Nó chỉ có một node gốc, nghĩa là một node không có node cha (trong trường hợp này là node 8).
- Và chỉ có một đường dẫn để đến bất kỳ node nào.
Vì vậy, node có giá trị 3 là con của node 8 và node cha của node 1 và 6. Và cách duy nhất để đến node 7 là đi qua 8, 3, 6 và 7.
Đó là một cây nhị phân. Bây giờ, điều khiến "Cây nhị phân" này trở thành "Cây tìm kiếm nhị phân" là giá trị của mỗi node lớn hơn tất cả các giá trị bên dưới cây con bên trái của node và nhỏ hơn giá trị bên dưới cây con bên phải của nó. Ví dụ: tất cả các giá trị bên dưới cây con bên trái của node 8 đều nhỏ hơn 8 và tất cả các giá trị bên dưới cây con bên phải của node 8 đều lớn hơn 8.
Khi biết điều này, mỗi lần chúng ta kiểm tra giá trị của một node và đó không phải là node chúng ta đang tìm kiếm, chúng ta biết rằng nếu giá trị nhỏ hơn, chúng ta phải tiếp tục tìm kiếm trên cây con bên trái và nếu nó lớn hơn, chúng ta phải tiếp tục đi trên cây con bên phải. Cho phép chúng ta Kiểu bỏ tất cả các node của nhánh khác và giảm một nửa kích thước của vấn đề. Giống như chúng ta đã làm trong ví dụ về từ điển.
Ok, vậy làm thế nào để chúng ta dịch mã này thành mã? Chà, Haskell làm cho nó dễ dàng một cách đáng ngạc nhiên.
data Sequence a = EmptyS | Node a (Sequence a) deriving (Show)
Trong Kiểu Sequence a của chúng ta, chúng ta có một trường hợp trong đó node trống và một trường hợp khi node có giá trị và trỏ đến phần còn lại của chuỗi.
Để tạo một BST, chúng ta hầu như cần cùng một Kiểu, ngoại trừ việc bây giờ chúng ta muốn chúng trỏ tới tối đa hai trình tự hiện là cây. Vì vậy, kiểu dữ liệu chúng ta cần là kiểu này:
data Tree a = EmptyT | Node a (Tree a) (Tree a) deriving (Show)
:t Node
node :: forall a. a -> Tree a -> Tree a -> Tree a
Và thế là xong! Sự khác biệt duy nhất nằm ở hàm tạo Node, hiện chứa một giá trị và hai cây con khác nhau.
Hãy trồng một vài cây:
-- data Tree a = EmptyT | Node a (Tree a) (Tree a)
emptyTree :: Tree a
emptyTree = EmptyT
oneLevelTree :: Tree Char
oneLevelTree = Node 'a' EmptyT EmptyT
twoLevelTree :: Tree Integer
twoLevelTree = Node 8
(Node 3 EmptyT EmptyT)
(Node 10 EmptyT EmptyT)
threeLevelTree :: Tree Integer -- Almost the same as the tree of the image
threeLevelTree = Node 8
(Node 3
(Node 1 EmptyT EmptyT)
(Node 6 EmptyT EmptyT)
)
(Node 10
EmptyT
(Node 14 EmptyT EmptyT)
)
Tuyệt vời. Chúng ta có Kiểu dữ liệu của chúng ta đã sẵn sàng để khuấy động! Bây giờ chúng ta cần triển khai hàm để kiểm tra xem một phần tử có nằm trong cây hay không.
Chúng ta bắt đầu với Kiểu, như mọi khi. Hàm sẽ lấy một giá trị kiểu a và một cây giá trị kiểu a. Nó sẽ kiểm tra xem giá trị có nằm trong cây hay không và trả về Bool giá trị True nếu có và False nếu không. Vì vậy, chúng ta có thể bắt đầu với một khai báo kiểu như thế này:
elemTree :: a -> Tree a -> Bool
Bây giờ, vì kiểu Tree có hai hàm tạo, chúng ta biết rằng có khả năng chúng ta sẽ cần hai định nghĩa (một định nghĩa cho mỗi hàm tạo) cho hai trường hợp. Một khi cây trống và một khi cây không có:
elemTree :: a -> Tree a -> Bool
elemTree v EmptyT = False
elemTree v (Node x left right) =...
Nếu cây trống, giá trị chúng ta cung cấp rõ ràng không có trong cây, vì vậy chúng ta trả về False.
Và nếu cây không trống thì sao? Chà, chúng ta chỉ khớp mẫu với node và có giá trị của nó ngay tại đó. Cũng có thể kiểm tra xem đó có phải là thứ chúng ta cần không:
elemTree :: (Eq a) => a -> Tree a -> Bool
elemTree v EmptyT = False
elemTree v (Node x left right) = if v == x then True else...
Bởi vì chúng ta đang kiểm tra xem giá trị của tham số đầu tiên có bằng giá trị bên trong cây hay không, nên chúng ta biết Kiểu a phải là một thể hiện của lớp Kiểu Eq. Vì vậy, chúng ta thêm ràng buộc đó vào khai báo.
Nếu bằng nhau ta quay lại True và kết thúc câu chuyện. Nhưng nếu không, chúng ta phải chọn cây con để tiếp tục tìm kiếm. Và điều đó phụ thuộc vào việc giá trị lớn hơn hay nhỏ hơn giá trị trong node. Vì vậy, chúng ta không chỉ phải kiểm tra xem giá trị có bằng nhau hay không mà còn lớn hơn hay nhỏ hơn giá trị của node.
elemTree :: (Ord a) => a -> Tree a -> Bool
elemTree v EmptyT = False
elemTree v (Node x left right)
| v == x = True
| v > x =...
| v < x =...
Bởi vì bây giờ chúng ta cũng phải sử dụng các hành vi > (lớn hơn) và < (nhỏ hơn), nên Kiểu phải là một thể hiện của lớp kiểu Ord. Và bởi vì (như chúng ta đã thấy trong bài học trước) để trở thành một thể hiện của lớp kiểu Ord, trước đó bạn phải là một thể hiện của lớp kiểu Eq, chúng ta có thể Kiểu bỏ ràng buộc đó và đặt ràng buộc Ord.
Ngoài ra, bởi vì chúng ta cần một loạt các câu lệnh if-else lồng nhau, chúng ta chuyển sang các bộ bảo vệ để có mã đơn giản hơn. Và bây giờ cho hai trường hợp cuối cùng:
elemTree :: (Ord a) => a -> Tree a -> Bool
elemTree v EmptyT = False
elemTree v (Node x left right)
| v == x = True
| v > x = elemTree v right
| v < x = elemTree v left
-- Examples
elemTree 6 threeLevelTree
elemTree 17 threeLevelTree
True
False
Nếu giá trị được cung cấp lớn hơn giá trị của node, chúng ta biết rằng—nếu giá trị nằm trong cây—thì giá trị đó sẽ nằm trong nhánh bên phải, nơi tất cả các giá trị đều lớn hơn giá trị của node hiện tại. Vì vậy, điều duy nhất chúng ta phải làm là kiểm tra đệ quy đúng cây con có cùng giá trị ban đầu.
Và nếu giá trị nhỏ hơn giá trị của node, chúng ta biết rằng—nếu giá trị ở trong cây—thì nó sẽ ở nhánh bên trái, nơi tất cả các giá trị đều nhỏ hơn giá trị của node hiện tại. Vì vậy, điều duy nhất chúng ta phải làm là kiểm tra đệ quy cây con bên trái với cùng một giá trị ban đầu.
Và thế là xong! Chúng ta có một cách để kiểm tra xem một giá trị có trong cấu trúc dữ liệu của chúng ta hay không bằng cách sử dụng thuật toán tìm kiếm nhị phân.
Đó là một giải pháp tuyệt vời. Vấn đề là, trong khi bạn đang suy nghĩ về tất cả những điều này, bạn đã quá tập trung vào những suy nghĩ của mình đến nỗi bạn không hề nhận ra rằng đã 15 phút trôi qua mà bạn không nói gì! Người phỏng vấn có một chút sợ hãi và nói với bạn rằng thật tuyệt khi được gặp bạn và họ sẽ liên lạc để Lưu ý cho bạn biết nếu bạn vượt qua cuộc phỏng vấn.
Vì vậy, điều rút ra là, trong cuộc phỏng vấn tiếp theo của bạn, hãy nhớ suy nghĩ thành tiếng trong khi giải quyết các vấn đề. Nó giúp người phỏng vấn biết quá trình suy nghĩ của bạn và bạn tránh thể hiện bộ mặt của mình khi xem say sưa các video Haskell. Vâng, một trong những bạn đang thực hiện ngay bây giờ.
Nhưng đừng lo, bạn sẽ có nhiều cơ hội giả định hơn. Hiện tại, chúng ta vẫn còn một vài điều nữa để xem ngày hôm nay. Ví dụ, thực tế là hình dạng của kiểu dữ liệu chỉ đạo cách bạn viết các hàm với nó.
Cấu trúc của kiểu dữ liệu định hình cách bạn viết các hàm với nó
Điều này không phải là bất biến, nhưng nói chung, bạn có một phương trình cho mỗi hàm tạo giá trị. Và nếu hàm tạo là đệ quy (một hoặc N lần), thì phương trình sẽ là đệ quy (một hoặc N lần).
Một vài ví dụ là:
-- data Box a = Empty | Has a
extract :: a -> Box a -> a
extract def Empty = def
extract _ (Has x) = x
Kiểu dữ liệu Box a có hai hàm tạo (Empty và Has) và không có hàm đệ quy nào.
Vì vậy, khi bạn viết một hàm cho kiểu dữ liệu này, có thể bạn sẽ cần viết hai công thức (có nghĩa là hai định nghĩa)—một hàm cho mỗi hàm tạo—và sẽ không có công thức nào có lệnh gọi đệ quy.
-- data Sequence a = EmptyS | a :-> (Sequence a)
elemSeq :: (Eq a) => a -> Sequence a -> Bool
elemSeq _ EmptyS = False
elemSeq x (y :-> ys) = x == y || elemSeq x ys
Kiểu dữ liệu Sequence a có hai hàm tạo (EmptyS và :->) và một trong các hàm tạo (:->) là hàm đệ quy (có (Sequence a) là tham số thứ hai).
Vì vậy, khi bạn viết một hàm cho kiểu dữ liệu này, có thể bạn sẽ cần viết hai công thức—một công thức cho mỗi hàm tạo—và công thức phù hợp với hàm tạo :-> sẽ có lệnh gọi đệ quy của hàm bạn đang xác định.
-- data Tree a = EmptyT | Node a (Tree a) (Tree a)
elemTree :: (Ord a) => a -> Tree a -> Bool
elemTree v EmptyT = False
elemTree v (Node x left right)
| v == x = True
| v > x = elemTree v right
| v < x = elemTree v left
Kiểu dữ liệu Tree a có hai hàm tạo (EmptyT và Node) và một trong các hàm tạo (Node) là đệ quy hai lần (hai lần (Tree a)).
Vì vậy, khi bạn viết một hàm cho kiểu dữ liệu này, có thể bạn sẽ cần viết hai công thức—một công thức cho mỗi hàm tạo—và công thức phù hợp với hàm tạo Node sẽ có hai lệnh gọi hàm đệ quy mà bạn đang xác định.
Tất nhiên, có những trường hợp khi quy tắc ngón tay cái này không được áp dụng. Nhưng bạn có thể sử dụng nó để bắt đầu bất cứ khi nào bạn không chắc về cách xác định hàm.
Như bạn có thể thấy, có quá nhiều thứ đang diễn ra với Kiểu, hàm tạo giá trị, hàm tạo kiểu, v.v. nên thật khó để theo dõi mọi thứ. Rất may, Haskell có một mánh khóe: Kinds !
Loại (Kinds)
Hãy quay trở lại những thứ đơn giản hơn. Bạn còn nhớ các Kiểu Box? KHÔNG à? Xem nào.. nó có một hàm tạo giá trị được gọi là Has. Hãy kiểm tra Kiểu của nó:
:t Has
Has :: forall a. a -> Box a
Thật tuyệt, vì vậy nó nhận một giá trị thuộc bất kỳ Kiểu nào và trả về một giá trị thuộc Kiểu Box a. Và những gì xảy ra với Kiểu Box đó? Làm thế nào tôi có thể biết thêm về nó? Nếu bạn cố kiểm tra Kiểu của một Kiểu, bạn sẽ gặp lỗi:
:t Box
<interactive>:1:1: error: Data constructor not in scope: Box
Nhưng có một cách để biết thêm về Kiểu đó. Chúng ta có thể sử dụng lệnh :i (info):
:i Box
type Box :: * -> *
data Box a = Empty | Has a -- Defined at :1:1
Dòng thứ hai là định nghĩa. Nhưng những dấu (*) ở dòng đầu tiên là cái quái gì vậy? Đó là Loại (Kinds) của Box. Tương tự như cách Kiểu của hàm tạo giá trị cung cấp cho bạn số lượng và Kiểu giá trị mà nó nhận, Loại của hàm tạo kiểu cung cấp cho bạn số lượng và Loại (Kinds) của Kiểu (Types) mà hàm tạo đó nhận.
Hãy để tôi nói rằng một lần nữa:
Kiểu của hàm tạo giá trị cung cấp cho bạn số lượng và Kiểu giá trị mà nó nhận.
Loại (Kind) của hàm tạo Kiểu (Type) cung cấp cho bạn số lượng và Loại (Kind) của Kiểu (Type) mà nó nhận.
Vì vậy, một Loại (kind) giống như là Kiểu (type) của một Kiểu (type) .
Bạn có thể đọc Kiểu như thế này:
*có nghĩa là: "Kiểu cụ thể" (một Kiểu không có bất kỳ tham số nào. Giống nhưFloat.)* -> *có nghĩa là: "hàm tạo kiểu (type) lấy một Kiểu cụ thể và trả về một Kiểu cụ thể khác" (Giống nhưBox a.)* -> (* -> *) -> *có nghĩa là: "hàm tạo kiểu nhận một Kiểu cụ thể và một hàm tạo kiểu tham số đơn và trả về một Kiểu cụ thể" (chúng ta chưa có ví dụ này.)- Và cứ như vậy
Một vài ví dụ:
Int, String, và những thứ tương tự giống như chúng là Kiểu cụ thể (concrete type).
-- Concrete types
:k Int
:k String
:k Bool
Int :: *
String :: *
Bool :: *
Như bạn có thể thấy, bạn cũng có thể kiểm tra Loại (kind) của một Kiểu (type) bằng cách sử dụng lệnh :k (:kind).
Box, Sequence, và Tree tất cả lấy một Kiểu cụ thể (String, Int, không quan trọng) và trả về một Kiểu cụ thể (Box Int, Sequence String, Tree Float).
-- Type constructor with one concrete type as parameter
:k Box
:k Sequence
:k Tree
Box :: * -> *
Sequence :: * -> *
Tree :: * -> *
Từ Kiểu tương đồng Entity lấy hai Kiểu cụ thể và trả về một Kiểu cụ thể (Entity String Bool).
-- Type constructor with two concrete types as parameters
-- type Entity a b = (a, b)
:k Entity
Entity :: * -> * -> *
Như bạn có thể thấy, Kiểu tương đồng cũng có Loại (kinds). Bởi vì chúng cũng có thể có các tham số Kiểu.
Ngoài ra, hãy lưu ý rằng ngay khi một hàm tạo kiểu nhận được tất cả các tham số của nó, nó sẽ trở thành một kiểu cụ thể:
:k Box
:k Box String
Box :: * -> *
Box String :: *
Và rằng bạn cũng có thể áp dụng một phần các hàm tạo kiểu, giống như với các hàm hoặc hàm tạo giá trị!:
data DoubleBox a b = Empty | Has a b deriving (Show)
:k DoubleBox
:k DoubleBox String
:k DoubleBox String Int
DoubleBox :: * -> * -> *
String DoubleBox :: * -> *
String DoubleBox Int :: *
Vì vậy, lần tới khi bạn cần biết thêm một chút về hàm tạo Kiểu (type), hãy kiểm tra Loại (kind) của nó!
Và bây giờ, để kết thúc bài giảng, tôi sẽ cung cấp cho bạn thêm một thông tin nhỏ xíu nữa. Nhưng đừng lo lắng. Bạn không cần phải học bất cứ điều gì hơn là một báo trước và một từ khóa duy nhất. Và đó là newType từ khóa.
Từ khóa newType
newType về cơ bản hoạt động giống như từ khóa data, ngoại trừ một lưu ý quan trọng:
Kiểu được tạo newType cần phải có chính xác một hàm tạo với chính xác một tham số/trường .
-- Like this:
newtype Color a = Color a
-- And this:
newtype Product a = Product { getProduct :: a }
Tuy nhiên, bạn cũng có thể làm điều đó với data. Vì vậy, tại sao sử dụng newType ?
Lý do ngắn gọn: Vì hiệu suất. Vì vậy, nếu bạn tình cờ tạo một kiểu dữ liệu với một hàm tạo và một tham số, bạn có thể chuyển từ khóa data thành newtype và nhận được việc tăng hiệu suất miễn phí.
Nguồn bài viết tại đây
